9 Distributed Applications
9.1 Definition
In a distributed system with several Erlang nodes, there may be a need to control applications in a distributed manner. If the node, where a certain application is running, goes down, the application should be restarted at another node.
Such an application is called a distributed application. Note that it is the control of the application which is distributed, all applications can of course be distributed in the sense that they, for example, use services on other nodes.
Because a distributed application may move between nodes, some addressing mechanism is required to ensure that it can be addressed by other applications, regardless on which node it currently executes. This issue is not addressed here, but the Kernel module global or STDLIB module pg can be used for this purpose.
9.2 Specifying Distributed Applications
Distributed applications are controlled by both the application controller and a distributed application controller process, dist_ac. Both these processes are part of the kernel application. Therefore, distributed applications are specified by configuring the kernel application, using the following configuration parameter (see also kernel(6)):
- distributed = [{Application, [Timeout,] NodeDesc}]
-
Specifies where the application Application = atom() may execute. NodeDesc = [Node | {Node,...,Node}] is a list of node names in priority order. The order between nodes in a tuple is undefined.
Timeout = integer() specifies how many milliseconds to wait before restarting the application at another node. Defaults to 0.
For distribution of application control to work properly, the nodes where a distributed application may run must contact each other and negotiate where to start the application. This is done using the following kernel configuration parameters:
- sync_nodes_mandatory = [Node]
- Specifies which other nodes must be started (within the timeout specified by sync_nodes_timeout.
- sync_nodes_optional = [Node]
- Specifies which other nodes can be started (within the timeout specified by sync_nodes_timeout.
- sync_nodes_timeout = integer() | infinity
- Specifies how many milliseconds to wait for the other nodes to start.
When started, the node will wait for all nodes specified by sync_nodes_mandatory and sync_nodes_optional to come up. When all nodes have come up, or when all mandatory nodes have come up and the time specified by sync_nodes_timeout has elapsed, all applications will be started. If not all mandatory nodes have come up, the node will terminate.
Example: An application myapp should run at the node cp1@cave. If this node goes down, myapp should be restarted at cp2@cave or cp3@cave. A system configuration file cp1.config for cp1@cave could look like:
[{kernel,
[{distributed, [{myapp, 5000, [cp1@cave, {cp2@cave, cp3@cave}]}]},
{sync_nodes_mandatory, [cp2@cave, cp3@cave]},
{sync_nodes_timeout, 5000}
]
}
].The system configuration files for cp2@cave and cp3@cave are identical, except for the list of mandatory nodes which should be [cp1@cave, cp3@cave] for cp2@cave and [cp1@cave, cp2@cave] for cp3@cave.
All involved nodes must have the same value for distributed and sync_nodes_timeout, or the behaviour of the system is undefined.
9.3 Starting and Stopping Distributed Applications
When all involved (mandatory) nodes have been started, the distributed application can be started by calling application:start(Application) at all of these nodes.
It is of course also possible to use a boot script (see Releases) which automatically starts the application.
The application will be started at the first node, specified by the distributed configuration parameter, which is up and running. The application is started as usual. That is, an application master is created and calls the application callback function:
Module:start(normal, StartArgs)
Example: Continuing the example from the previous section, the three nodes are started, specifying the system configuration file:
> erl -sname cp1 -config cp1 > erl -sname cp2 -config cp2 > erl -sname cp3 -config cp3
When all nodes are up and running, myapp can be started. This is achieved by calling application:start(myapp) at all three nodes. It is then started at cp1, as shown in the figure below.
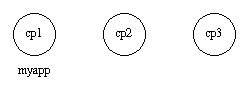
Figure 9.1: Application myapp - Situation 1
Similarly, the application must be stopped by calling application:stop(Application) at all involved nodes.
9.4 Failover
If the node where the application is running goes down, the application is restarted (after the specified timeout) at the first node, specified by the distributed configuration parameter, which is up and running. This is called a failover.
The application is started the normal way at the new node, that is, by the application master calling:
Module:start(normal, StartArgs)
Exception: If the application has the start_phases key defined (see Included Applications), then the application is instead started by calling:
Module:start({failover, Node}, StartArgs)where Node is the terminated node.
Example: If cp1 goes down, the system checks which one of the other nodes, cp2 or cp3, has the least number of running applications, but waits for 5 seconds for cp1 to restart. If cp1 does not restart and cp2 runs fewer applications than cp3, then myapp is restarted on cp2.
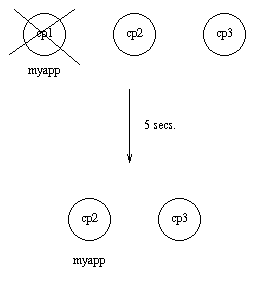
Figure 9.2: Application myapp - Situation 2
Suppose now that cp2 goes down as well and does not restart within 5 seconds. myapp is now restarted on cp3.
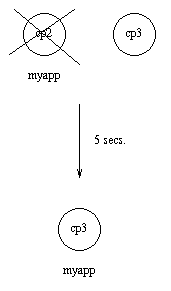
Figure 9.3: Application myapp - Situation 3
9.5 Takeover
If a node is started, which has higher priority according to distributed, than the node where a distributed application is currently running, the application will be restarted at the new node and stopped at the old node. This is called a takeover.
The application is started by the application master calling:
Module:start({takeover, Node}, StartArgs)where Node is the old node.
Example: If myapp is running at cp3, and if cp2 now restarts, it will not restart myapp, because the order between nodes cp2 and cp3 is undefined.
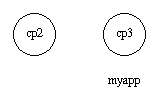
Figure 9.4: Application myapp - Situation 4
However, if cp1 restarts as well, the function application:takeover/2 moves myapp to cp1, because cp1 has a higher priority than cp3 for this application. In this case, Module:start({takeover, cp3@cave}, StartArgs) is executed at cp1 to start the application.
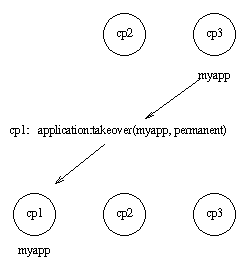
Figure 9.5: Application myapp - Situation 5