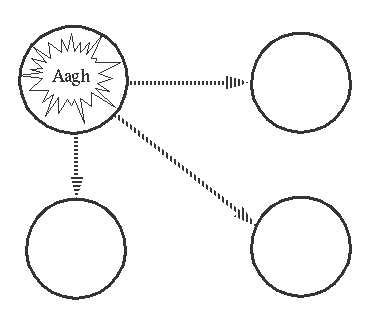

Now suppose process A fails - exit signals start to propogate through the links:
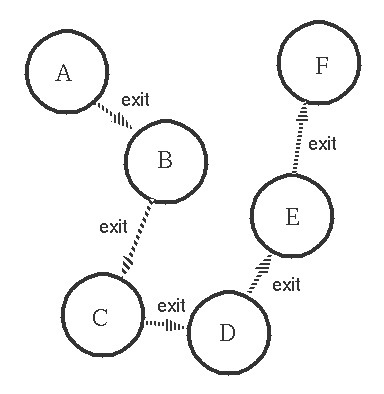
These exit signals eventuall reach all the processes which are linked together.
The rule for propagating errors is: If the process which receives an exit signal, caused by an error, is not trapping exits then the process dies and sends exit signals to all its linked processes.
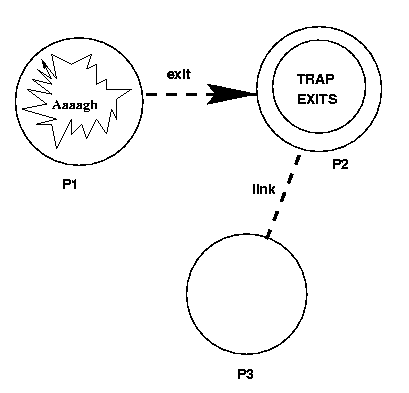
P2 has the following code:
receive
{'EXIT', P1, Why} ->
... exit signals ...
{P3, Msg} ->
... normal messages ...
end
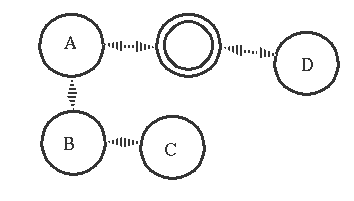
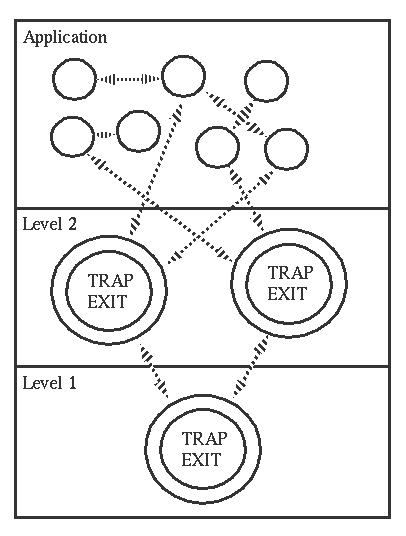
The process marked with a double ring is an error trapping process.
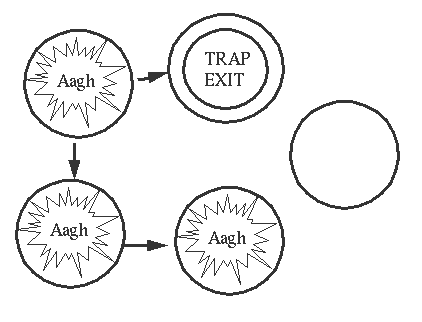
If an error occurs in any of A, B, or C then All of these process will die (through propagation of errors). Process D will be unaffected.
In a well designed system we can arrange that application programers will not have to write any error handling code since all error handling is isolated to deper levels in the system.
The receive .. end construct attempts to remove messages from the mailbox of the current process. Exit signals which arrive at a process either cause the process to crash (if the process is not trapping exit signals) or are treated as normal messages and placed in the process mailbox (if the process is trapping exit signals). Exit signals are sent implicitly (as a result of evaluating a BIF with incorrect arguments) or explicitly (using exit(Pid, Reason), or exit(Reason) ).
If Reason is the atom normal - the receiving process ignores the signal (if it is not trapping exits). When a process terminates without an error it sends normal exit signals to all linked processes. Don't say you didn't ask!
This is unreliable - What happens if the client crashes before it sends the release message?
top(Free, Allocated) ->
receive
{Pid, alloc} ->
top_alloc(Free, Allocated, Pid);
{Pid ,{release, Resource}} ->
Allocated1 = delete({Resource,Pid},ĀAllocated),
top([Resource|Free], Allocated1)
end.
top_alloc([], Allocated, Pid) ->
Pid ! no,
top([], Allocated);
top_alloc([Resource|Free], Allocated, Pid) ->
Pid ! {yes, Resource},
top(Free, [{Resource,Pid}|Allocated]).
This is the top loop of an allocator with no
error recovery. Free is a list of unreserved
resources. Allocated is a list of pairs
{Resource, Pid} - showing which resource
has been allocated to which process.
The server is linked to the client during the time interval when the resource is allocted. If an exit message comes from the client during this time the resource is released.
top_recover_alloc([], Allocated, Pid) ->
Pid ! no,
top_recover([], Allocated);
top_recover_alloc([Resource|Free], Allocated, Pid) ->
%% No need to unlink.
Pid ! {yes, Resource},
link(Pid),
top_recover(Free, [{Resource,Pid}|Allocated]).
top_recover(Free, Allocated) ->
receive
{Pid , alloc}Ā->
top_recover_alloc(Free, Allocated, Pid);
{Pid, {release, Resource}}Ā->
unlink(Pid),
Allocated1 = delete({Resource, Pid}, Allocated),
top_recover([Resource|Free], Allocated1);
{'EXIT', Pid, Reason}Ā->
%% No need to unlink.
Resource = lookup(Pid, Allocated),
Allocated1 = delete({Resource, Pid}, Allocated),
top_recover([Resource|Free], Allocated1)
end.
Not done -- multiple allocation to same
process. i.e. before doing the unlink(Pid) we
should check to see that the process has not
allocated more than one device.
delete(H, [H|T]) ->
T;
delete(X, [H|T]) ->
[H|delete(X, T)].
lookup(Pid, [{Resource,Pid}|_]) ->
Resource;
lookup(Pid, [_|Allocated]) ->
lookup(Pid, Allocated).